

Data Engineering on Microsoft Azure DP-203

The DP-203 Data Engineering on Microsoft Azure Course is an educational program that guides participants through the skills and knowledge needed to become expert data engineers in the Microsoft Azure ecosystem. The course is designed to teach participants how to design, build, operate, and secure data processing solutions on Azure. During the course, participants will focus on using various Azure services and technologies to build and operate scalable and efficient data engineering solutions. They will learn how to work with Azure Data Factory, Azure Synapse Analytics, Azure Databricks, and Azure Stream Analytics, among other services. The course also covers designing and implementing data storage solutions, real-time and batch data processing, and managing data security and compliance. The classes are structured to provide a balance of theory and practice, allowing participants to understand key concepts and immediately apply the skills they have learned through exercises and projects. This approach ensures that participants have a solid theoretical foundation and solid practical experience in working with data engineering solutions on Azure. This course helps prepare you for the Azure Data Engineer Associate Certification exam.
Course Objectives
Below is a summary of the main objectives of the Data Engineering on Microsoft Azure DP-203 Course :
- Learn how to use Azure services for data engineering.
- Design and manage data processing solutions.
- Work with tools like Azure Data Factory and Azure Databricks.
- Manage data security and compliance.
- Apply the skills acquired through exercises and projects.
- Data Storage and Management: Learn strategies for efficient data storage and management on Azure, including use cases for Azure Blob Storage, Azure SQL Database, and Azure Cosmos DB.
- Real-time Data Processing: Explore techniques and tools for implementing real-time data processing solutions on Azure, leveraging services like Azure Stream Analytics and Event Hubs.
- Big Data and Advanced Analytics: Gain insights into handling big data workloads on Azure, including integrating with services such as Azure Synapse Analytics and applying advanced analytics techniques for data-driven decision-making
Course Certification
This course helps you prepare to take the:
Exam DP-203 Azure Data Engineer Associate ;
Course Outline
Implement a partition strategy
- Implement a partition strategy for files
- Implement a partition strategy for analytical workloads
- Implement a partition strategy for streaming workloads
- Implement a partition strategy for Azure Synapse Analytics
- Identify when partitioning is needed in Azure Data Lake Storage Gen2
Design and implement the data exploration layer
- Create and execute queries by using a compute solution that leverages SQL serverless and Spark cluster
- Recommend and implement Azure Synapse Analytics database templates
- Push new or updated data lineage to Microsoft Purview
- Browse and search metadata in Microsoft Purview Data Catalog
Ingest and transform data
- Design and implement incremental loads
- Transform data by using Apache Spark
- Transform data by using Transact-SQL (T-SQL) in Azure Synapse Analytics
- Ingest and transform data by using Azure Synapse Pipelines or Azure Data Factory
- Transform data by using Azure Stream Analytics
- Cleanse data
- Handle duplicate data
- Avoiding duplicate data by using Azure Stream Analytics Exactly Once Delivery
- Handle missing data
- Handle late-arriving data
- Split data
- Shred JSON
- Encode and decode data
- Configure error handling for a transformation
- Normalize and denormalize data
- Perform data exploratory analysis
Develop a batch processing solution
- Develop batch processing solutions by using Azure Data Lake Storage, Azure Databricks, Azure Synapse Analytics, and Azure Data Factory
- Use PolyBase to load data to a SQL pool
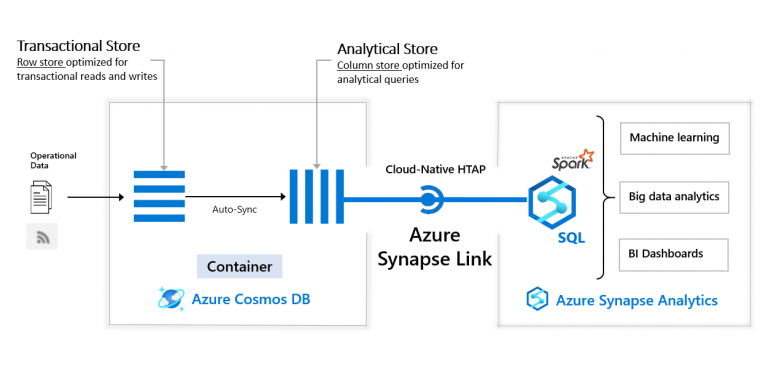
- Implement Azure Synapse Link and query the replicated data
- Create data pipelines
- Scale resources
- Configure the batch size
- Create tests for data pipelines
- Integrate Jupyter or Python notebooks into a data pipeline
- Upsert data
- Revert data to a previous state
- Configure exception handling
- Configure batch retention
- Read from and write to a delta lake
Develop a stream processing solution
- Create a stream processing solution by using Stream Analytics and Azure Event Hubs
- Process data by using Spark structured streaming
- Create windowed aggregates
- Handle schema drift
- Process time series data
- Process data across partitions
- Process within one partition
- Configure checkpoints and watermarking during processing
- Scale resources
- Create tests for data pipelines
- Optimize pipelines for analytical or transactional purposes
- Handle interruptions
- Configure exception handling
- Upsert data
- Replay archived stream data
Manage batches and pipelines
- Trigger batches
- Handle failed batch loads
- Validate batch loads
- Manage data pipelines in Azure Data Factory or Azure Synapse Pipelines
- Schedule data pipelines in Data Factory or Azure Synapse Pipelines
- Implement version control for pipeline artifacts
- Manage Spark jobs in a pipeline
Implement data security
- Implement data masking
- Encrypt data at rest and in motion
- Implement row-level and column-level security
- Implement Azure role-based access control (RBAC)
- Implement POSIX-like access control lists (ACLs) for Data Lake Storage Gen2
- Implement a data retention policy
- Implement secure endpoints (private and public)
- Implement resource tokens in Azure Databricks
- Load a DataFrame with sensitive information
- Write encrypted data to tables or Parquet files
- Manage sensitive information
Monitor data storage and data processing
- Implement logging used by Azure Monitor
- Configure monitoring services
- Monitor stream processing
- Measure performance of data movement
- Monitor and update statistics about data across a system
- Monitor data pipeline performance
- Measure query performance
- Schedule and monitor pipeline tests
- Interpret Azure Monitor metrics and logs
- Implement a pipeline alert strategy
Optimize and troubleshoot data storage and data processing
- Compact small files
- Handle skew in data
- Shop computer games
- Optimize resource management
- Tune queries by using indexers
- Tune queries by using cache
- Troubleshoot a failed Spark job
- Troubleshoot a failed pipeline run, including activities executed in external services
Course Mode
Instructor-Led Remote Live Classroom Training;
Trainers
Trainers are authorized Instructors in Microsoft and certified in other IT technologies, with years of hands-on experience in the industry and in Training.
Lab Topology
For all types of delivery, the participant can access the equipment and actual systems in our laboratories or directly in international data centers remotely, 24/7. Each participant has access to implement various configurations, Thus immediately applying the theory learned. Below are some scenarios drawn from laboratory activities.
Course Details
Course Prerequisites
Participation in the Azure Administrator course is recommended .
Course Duration
Intensive duration 4 days;
Course Frequency
Course Duration: 4 days (9.00 to 17.00) - Ask for other types of attendance.
Course Date
- Azure Security Technologies Course (Intensive Formula) – On request – 09:00 – 17:00
Steps to Enroll
Registration takes place by asking to be contacted from the following link, or by contacting the office at the international number +355 45 301 313 or by sending a request to the email info@hadartraining.com
