
Building Batch Data Analytics Solutions on AWS

The Building Batch Data Analytics Solutions on AWS (DABATC) course is designed to teach students how to build batch data analytics solutions using Amazon EMR, an enterprise-grade managed Apache Spark and Apache Hadoop service. Students will learn how Amazon EMR integrates with open source projects such as Apache Hive, Hue, and HBase, and with AWS services such as AWS Glue and AWS Lake Formation. The course covers data collection, ingestion, cataloging, storage, and processing in the context of Spark and Hadoop. Students will use EMR notebooks to support both analytics and machine learning workloads, and apply security, performance, and cost management best practices to operating Amazon EMR. This course helps prepare students for the AWS Certified Data Engineer – Associate certification .
Course Objectives
Below is a summary of the main objectives of the Building Batch Data Analytics Solutions on AWS (DABATC) course :
- Build batch data analytics solutions using Amazon EMR, a service that manages Apache Spark and Apache Hadoop.
- Amazon EMR integration with open source projects (Apache Hive, Hue, HBase) and AWS services (AWS Glue, AWS Lake Formation).
- Managing data collection, ingestion, cataloging, storage and processing components in the context of Spark and Hadoop.
- Using EMR notebooks to support both analytics and machine learning workloads.
- Apply security, performance, and cost management best practices to your Amazon EMR operations.
- Optimize EMR cluster configurations for performance and cost efficiency.
- Implement data governance and compliance strategies for batch data processing.
- Troubleshoot and resolve common issues related to batch data analytics and EMR clusters.
Course Certification
This course helps you prepare to take the:
AWS Certified Data Engineer – Associate Exam ;
Course Outline
Module 0: Overview of Data Analytics and the Data Pipeline
- Data analytics use cases
- Using the data pipeline for analytics
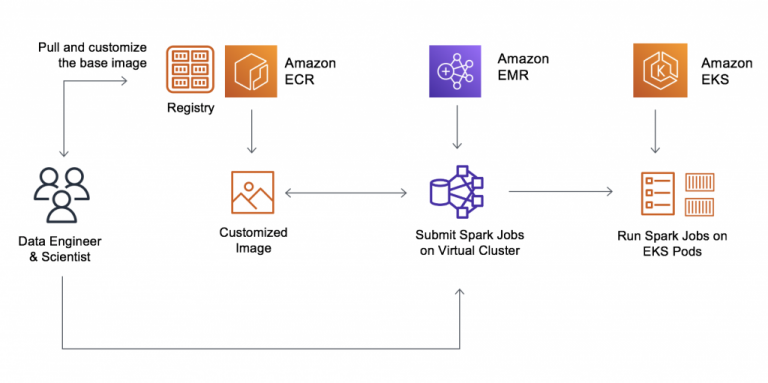
Module 1: Introduction to Amazon EMR
- Using Amazon EMR in analytics solutions
- Amazon EMR cluster architecture
- Interactive Demo 1: Launching an Amazon EMR cluster
- Cost management strategies
Module 2: Data Analytics Pipeline Using Amazon EMR: Ingestion and Storage
- Storage optimization with Amazon EMR
- Data ingestion techniques
Module 3: High-Performance Batch Data Analytics Using Apache Spark on Amazon EMR
- Apache Spark on Amazon EMR use cases
- Why Apache Spark on Amazon EMR
- Spark concepts
- Interactive Demo 2: Connect to an EMR cluster and perform Scala commands using the
- Spark shell
- Transformation, processing, and analytics
- Using notebooks with Amazon EMR
- Practice Lab 1: Low-latency data analytics using Apache Spark on Amazon EMR
Module 4: Processing and Analyzing Batch Data with Amazon EMR and Apache Hive
- Using Amazon EMR with Hive to process batch data
- Transformation, processing, and analytics
- Practice Lab 2: Batch data processing using Amazon EMR with Hive
- Introduction to Apache HBase on Amazon EMR
Module 5: Serverless Data Processing
- Serverless data processing, transformation, and analytics
- Using AWS Glue with Amazon EMR workloads
- Practice Lab 3: Orchestrate data processing in Spark using AWS Step Functions
Module 6: Security and Monitoring of Amazon EMR Clusters
- Securing EMR clusters
- Interactive Demo 3: Client-side encryption with EMRFS
- Monitoring and troubleshooting Amazon EMR clusters
- Demo: Reviewing Apache Spark cluster history
Module 7: Designing Batch Data Analytics Solutions
- Batch data analytics use cases
- Activity: Designing a batch data analytics workflow
- Module B: Developing Modern Data Architectures on AWS
- Modern data architectures
Course Mode
Instructor-Led Remote Live Classroom Training;
Trainers
Trainers are Amazon AWS accredited instructors and certified in other IT technologies, with years of practical experience in the sector and in training.
Lab Topology
For all types of delivery, the participant can access the equipment and actual systems in our laboratories or directly in international data centers remotely, 24/7. Each participant has access to implement various configurations, Thus immediately applying the theory learned. Below are some scenarios drawn from laboratory activities.
Course Details
Course Prerequisites
Participation in the following courses is recommended:
- Architecting on AWS
- Building Data Lakes on AWS
- AWS Hadoop Fundamentals
Course Duration
Intensive duration 1 days;
Course Frequency
Course Duration: 1 days (9.00 to 17.00) - Ask for other types of attendance.
Course Date
- Building Batch Data Analytics Solutions on AWS(Intensive Formula) – On Request – 9:00 – 17:00
Steps to Enroll
Registration takes place by asking to be contacted from the following link, or by contacting the office at the international number +355 45 301 313 or by sending a request to the email info@hadartraining.com
